OCLC has filed suit against the company Clarivate which owns Proquest and ExLibris. The suit focuses on a metadata service proposed by Ex Libris called "MetaDoor." MetaDoor isn't a bibliographic database à la WorldCat, it is a peer-to-peer service that allows its users to find quality records in the catalog systems of other libraries. ("MetaDoor" is a terrible name for a product, by the way.)
What seems to specifically have OCLC's dander up is that Ex Libris states that it will allow any and all libraries, not just its Alma customers, to use this service for free. As the service does not yet exist it is unknown how it could affect the library metadata sharing environment. It may succeed, it may fail. If it succeeds, the technology that Ex Libris develops will be a logical next step in bibliographic data sharing, but its effect on OCLC is hard to predict.
Yesterday's and Today's Technology
WorldCat is yesterday's technology: a huge, centralized database. Peer-to-peer sharing of bibliographic records has been available since the 1980's with the development of the Z39.50 protocol, and presumably a considerable amount of sharing over that protocol has been used by libraries to obtain records from other libraries. Over the years many programs and systems have been developed to make use of Z39.50 and the protocol is built in to library systems, both for obtaining records and for sharing records.
The actual extent of peer-to-peer sharing of bibliographic records already today does not seem to be known, although I did only a brief amount of research looking for that information. It is definitely in use in library environments where participation in OCLC is unaffordable; articles vaunt its use in Russia, India, Korea, and other countries. It is built into the open source library system Koha that is aimed at those libraries that are priced out of the mainstream library systems market. Where libraries have known peers, such as the national library of a country, peer-to-peer makes good sense.
What OCLC's centralized database has that peer-to-peer lacks (at least to date) is consolidated library holdings information. As Kyle Banerjee said on Twitter, the real value in WorldCat is the holdings. This is used by interlibrary loan systems, and it is what appears on the screen when you do a WorldCat search. Cleverly, OCLC has recorded the geographical location of all of its holding libraries and can give you a list of libraries relative to your location. In the past this type of service was only available through a central database, but we may have arrived at point where peer-to-peer could provide this as well.
A couple of other things before I look at some specific points in the lawsuit. One is that WorldCat is not the only bibliographic database used for sharing of metadata. Some smaller library companies also have their own shared databases. These are much smaller than WorldCat and the libraries that use them generally are 1) unable to afford OCLC's member fees and 2) do not have need of the depth or breadth of WorldCat's bibliographic data. For example, the CARL database from TLC company has a database of 77 million records, many less than worldCat's over 500 million. Even the Library of Congress catalog is only 20 million strong. The value for some libraries is that WorldCat contains the long tail; for others, that long tail is not needed. It's the difference between the Harvard library and your local public library. Harvard may well have need for metadata for a Lithuanian poetry journal, your local public library can do just fine with a peer database of popular works published in the US.
And another: we're slowly moving to a less "thing"-based world to a "data"-based world. Yes, scholars still need books and journals, but increasingly our information seeking returns tiny bites, not big thoughts. You can rue that, but I think it's only going to get worse. It's like the difference between a Ken Burns 10-part documentary on the Civil War and TikTok. The metadata creation activity for the deep thoughts of books and articles is not viable for YouTube, Instagram, TikTok or even Facebook. Us "book people" are hanging on to a vast repository that is less and less looking forward and more and more becoming dusty and crusty. We don't want to lose that valuable archive, but it is hard to claim that we are not a fading culture.
OK, to the lawsuit.
What is the Nut of this Case?
OCLC claims in its suit that Clarivate is undertaking MetaDoor as a malicious act, targeting WorldCat with a desire to destroy it. I don't think you need to be malicious to come up with a project to create an efficient system for sharing bibliographic records. Creating a shared database at this time is simply a logical need for any data service.
The main fact behind OCLC's suit is that uploading library catalog bibliographic records to
MetaDoor is a violation of the libraries' contracts with OCLC, and that Clarivate/Ex Libris is encouraging libraries to violate their contracts. As
Clarivate has no such contract with OCLC, the suit uses terms like "conspiracy" and a lot of "tortious" to describe that Clarivate/Ex Libris is
breaking some law of competition by encouraging OCLC customers to violate their contracts.
I'm not sure how that will play in court but you can see on the Clarivate site that one of their main areas of expertise is in intellectual property around data. Regardless of the outcome of this suit we may get to see some interesting arguments around data ownership. It's still a wide-open area where some smart discussion would be very welcome.
The ILS Market
The lawsuit complains that Clarivate has become the largest player in the ILS market through its purchase of systems like Ex Libris and ProQuest. (It isn't clear to me how "large" is defined here.) It also bemoans the consolidation of the library market. The library market is hardly unique in this; consolidation of this type is a normal course of things in our barely-regulated capitalism. It is, as always, hard to understand just what Clarivate owns because Clarivate owns Proquest which owns Ex Libris which owns Innovative Interfaces which owns SkyRiver and VTLS, among others. The number of players in the library market, which once was a handful of independent companies, is shrinking at a rapid rate, and this has been a worry in the library world now for decades.
On its web site Clarivate presents itself as a research data and analytics company. It includes Proquest and Web of Science in its list of offerings, but interestingly makes no mention of Ex Libris. I've always wondered why anyone with any business sense would want to enter the library cataloging systems market. In fact, Clarivate inherited Ex Libris when it purchased Proquest, and the Clarivate press release upon acquiring Proquest makes no mention of Ex Libris or other library systems.
Speaking of market consolidation, one must remember that at one time OCLC had two rather large competitors in the library cataloging market: the Western Library Network and Research Libraries Information Network. OCLC purchased both of these, and they then ceased to exist. That was itself a consolidation that concerned many because at the time few library cataloging systems provided a significantly large database to support the cataloging activity. Also, take a gander at this chart from Marshall Breeding's Library Tech Guides that shows the "mergers and acquisitions" of OCLC:
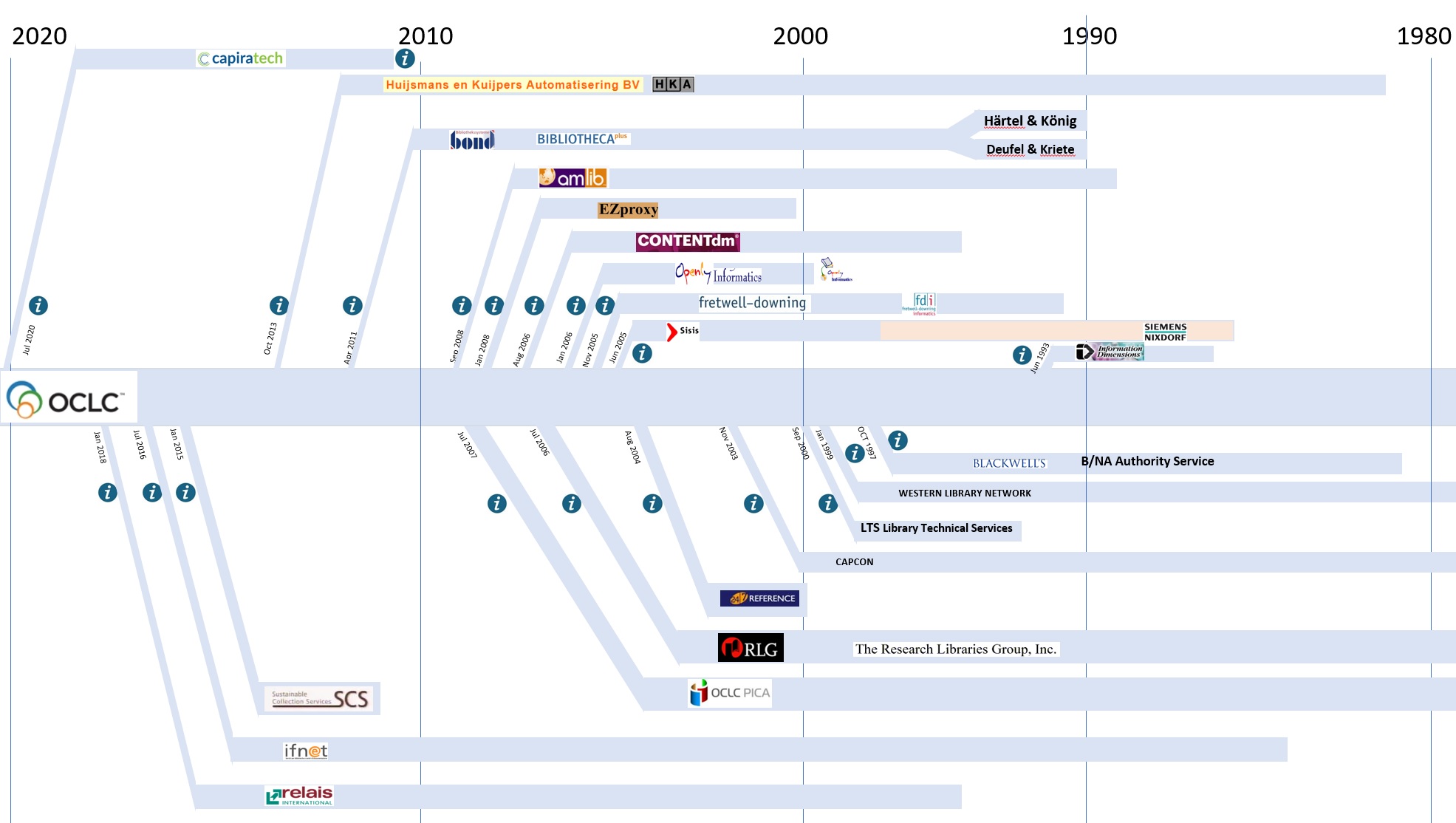
(more readable on Marshall's site, so hop over there fore details)
What is a WorldCat record?
The lawsuit speaks of the "theft" of WorldCat records by Ex Libris for their MetaDoor product (which isn't well explained as the records will be voluntarily offered by the participating libraries). The peer-to-peer action of MetaDoor, however, does not touch the WorldCat database directly. As I understand it from the Ex Libris web site, libraries using the Ex Libris system agree to have that system harvest records from their database. Information from those records will be indexed in MetaDoor but the records themselves will not stored there. Users of MetaDoor will discover records they need for cataloging through MetaDoor, and the records will be retrieved from the library system holding the record. Without a doubt, some of those records will have been downloaded by libraries during cataloging on OCLC. The lawsuit refers to these as "WorldCat records."
Here's the hitch: these are records are distributed among individual library databases. Each MARC record is a character string in which any part of that string can be modified using software written for that purpose. That software may be part of the library catalog system, or it may be standalone software like the open software MARCedit. Other software, like Open Refine, has been incorporated into batch workflows for MARC records to make changes to records. Basically, the records undergo a lot of changes, both the "enhancements" in WorldCat that the lawsuit refers to but also an unknown quantity of modifications once individual libraries obtain them.
Note that some libraries do not use OCLC and therefore have no WorldCat records, and many libraries have multiple sources of bibliographic data. It simply isn't possible to say "all your MARC belong to us." It's much more complicated than that. Although there is nominally both provenance and versioning data in the MARC records, these fields are as editable as all others. In addition, some systems ignore these and do not attempt to update those details as the records are edited. This means that there is no way to look at a record in a library database and determine precisely from where it was originally obtained prior to being in that database. If library A uses OCLC to create a catalog record and library B (not an OCLC cataloging customer) uses its catalog system's Z39.50 option to copy that record from Library A, modifying the record for its own purposes, then library C obtains the record from Library B ... well, you see the problem. These records may flow throughout the library catalog universe, losing their identity as WorldCat records with each step.
OCLC appears to claim in its suit that the OCLC number confers some kind of ownership stamp on the records. In one of the later paragraphs of a very insightful Scholarly Kitchen blog post, Todd Carpenter reminds us that OCLC has not claimed restrictions on the identification number. Also, like everything else in the MARC record, that number can be deleted, modified, or added to a record at the whim of the cataloger. (OK, I admit that "whim" and "cataloger" probably shouldn't be used in the same sentence.)
Rather than flinging lawsuits around, it would be very interesting to use that money to hire one of those people who looks out 20 years to tell you what the environment will be and what you should be investing in today. I can cover a certain amount of the past, but the future is a fog to me. I hope someone has ideas.
-----
As with many lawsuits, there's a lot of flinging documentation back and forth. Check out this site to keep an eye on things. I welcome recommendations of other resources.
No comments:
Post a Comment